ELMo: 다중 레이어 임베딩의 언어 모델 혁신
ELMo는 다층 임베딩을 활용한 언어 모델로, 단어의 의미를 더 잘 파악할 수 있다. 이 알고리즘은 자연어 처리 분야에서 문맥을 고려한 더욱 효과적인 텍스트 이해를 제공한다.
ELMo: 언어 모델의 다중 레이어 임베딩
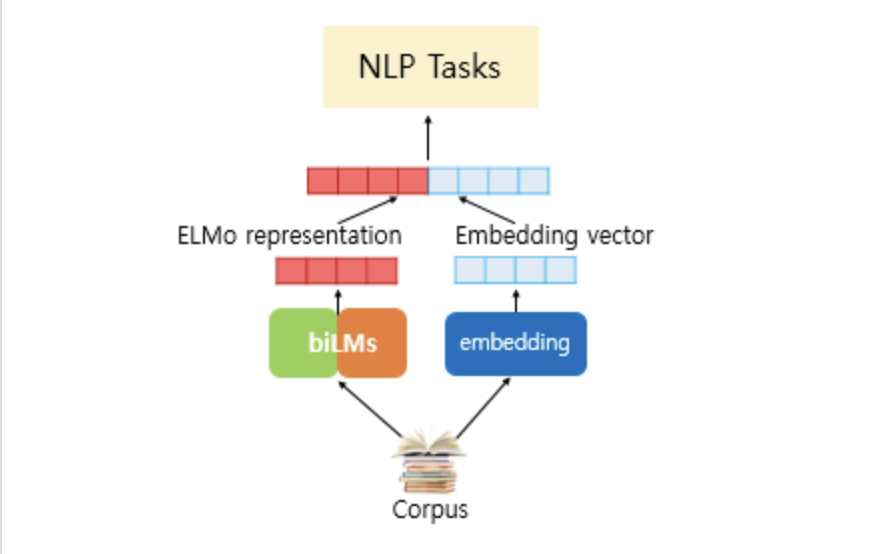
ELMo 알고리즘 소개
ELMo(Embeddings from Language Models)는 다층 임베딩을 활용한 언어 모델로, 단어의 의미를 더 잘 파악할 수 있다. 이번 섹션에서는 ELMo 알고리즘의 개요와 원리에 대해 알아보겠다.
ELMo의 개요
ELMo(Embeddings from Language Models)는 2018년에 제안된 딥러닝 기반의 언어 모델입니다. ELMo는 사전 훈련된 언어 모델을 사용하여 단어의 문맥적 의미를 임베딩하는 방법을 제공합니다.
주요 특징과 개요는 다음과 같습니다:
- 양방향 LSTM: ELMo는 양방향 LSTM(Bidirectional Long Short-Term Memory)을 사용하여 문장의 양쪽 방향으로 문맥을 고려합니다. 이를 통해 단어의 문맥적 의미를 더 잘 파악할 수 있습니다.
- 사전 훈련된 모델: ELMo는 대규모 텍스트 코퍼스를 사용하여 사전 훈련된 언어 모델을 학습합니다. 이를 통해 문장의 다양한 문맥을 학습하고 단어의 의미를 효과적으로 캡처할 수 있습니다.
- 다양한 응용 분야: ELMo 임베딩은 텍스트 분류, 개체명 인식, 기계 번역 등 다양한 자연어 처리 작업에 사용될 수 있습니다. 또한 ELMo는 다른 모델과 함께 사용하여 성능을 향상시키는 데에도 활용됩니다.
ELMo의 등장은 언어 모델을 사용한 단어 임베딩에 새로운 관점을 제공하고 자연어 처리 분야에서의 성능을 향상시켰습니다.
ELMo의 원리
ELMo(Embeddings from Language Models)는 양방향 LSTM(Bidirectional Long Short-Term Memory)을 기반으로 하는 언어 모델입니다. ELMo의 원리는 다음과 같습니다:
- 사전 훈련된 언어 모델: ELMo는 대규모 텍스트 코퍼스를 사용하여 사전 훈련된 언어 모델을 구축합니다. 이 모델은 양방향 LSTM을 기반으로 하며, 각 단어에 대한 문맥을 고려하여 단어의 의미를 파악합니다.
- 단어 임베딩: 주어진 문장에서 각 단어의 입력 토큰을 모델에 전달하여 언어 모델을 통해 각 단어의 임베딩을 생성합니다. 이 때, 양방향 LSTM을 사용하므로 각 단어의 임베딩은 해당 단어의 좌우 문맥을 모두 반영합니다.
- 다양한 층의 표현: ELMo는 각 단어의 임베딩을 생성하는 데에 여러 층의 언어 모델을 사용합니다. 이를 통해 각 단어의 다양한 추상화 수준의 표현을 얻을 수 있습니다.
- 동적 임베딩: 주어진 문장에서 각 단어의 임베딩은 해당 단어의 문맥에 따라 동적으로 조절됩니다. 따라서 같은 단어라도 문맥에 따라 다른 임베딩이 생성됩니다.
이러한 방식으로 생성된 ELMo 임베딩은 단어의 문맥적 의미를 효과적으로 표현하며, 다양한 자연어 처리 작업에 활용될 수 있습니다.
ELMo의 응용
텍스트 분류
텍스트 분류는 자연어 처리(Natural Language Processing, NLP)의 주요 작업 중 하나로, 주어진 텍스트를 사전에 정의된 범주 또는 클래스로 분류하는 과정을 의미합니다. 주요 내용은 다음과 같습니다:
- 텍스트 데이터 수집: 텍스트 분류 작업을 위해 레이블이 지정된 텍스트 데이터를 수집합니다. 이 데이터는 각 문서나 문장이 어떤 범주에 속하는지를 나타내는 레이블을 포함합니다.
- 데이터 전처리: 수집된 텍스트 데이터를 전처리하여 모델에 입력할 수 있는 형식으로 변환합니다. 이 과정에는 토큰화, 불용어 제거, 특수 문자 제거, 정규화 등이 포함될 수 있습니다.
- 모델 선택: 텍스트 분류를 위한 적합한 모델을 선택합니다. 주로 사용되는 모델로는 로지스틱 회귀, 나이브 베이즈, 서포트 벡터 머신(SVM), 딥러닝 모델(예: 컨볼루션 신경망, 순환 신경망) 등이 있습니다.
- 모델 훈련: 선택한 모델을 훈련 데이터에 적합하도록 학습시킵니다. 이 과정은 입력 텍스트와 해당 레이블을 사용하여 모델의 가중치를 조정하는 것을 포함합니다.
- 모델 평가: 테스트 데이터를 사용하여 훈련된 모델의 성능을 평가합니다. 일반적으로 정확도, 정밀도, 재현율, F1 점수 등의 지표를 사용하여 모델의 성능을 측정합니다.
- 모델 적용: 훈련된 모델을 새로운 텍스트 데이터에 적용하여 분류 작업을 수행합니다. 이를 통해 새로운 텍스트가 주어졌을 때 해당 텍스트가 어떤 범주에 속하는지를 예측할 수 있습니다.
텍스트 분류는 스팸 메일 필터링, 감성 분석, 문서 분류, 주제 분류 등 다양한 응용 분야에서 활용되며, 자연어 처리 기술의 핵심적인 부분입니다.
질문 응답
ELMo는 질문 응답 시스템에서도 탁월한 성능을 발휘한다. 자연어로 된 질문에 대해 텍스트 데이터에서 정확한 답변을 찾아내는 데 활용된다.
기계 번역
ELMo는 기계 번역 분야에서도 많은 연구가 이루어지고 있다. 이전의 모델보다 더욱 자연스러운 번역 결과를 얻을 수 있으며, 다국어 번역에도 효과적으로 적용된다.
ELMo의 효과적인 활용

문맥 파악
ELMo는 다층 임베딩을 사용하여 단어의 다양한 의미와 문맥을 고려한다. 이를 통해 텍스트 이해의 정확성과 품질을 높일 수 있다.
다양한 자연어 처리 작업
자연어 처리(Natural Language Processing, NLP)는 다양한 작업을 수행할 수 있는 분야입니다. 주요 자연어 처리 작업과 각 작업에 대한 개요는 다음과 같습니다:
-
텍스트 분류:
텍스트 분류는 주어진 텍스트를 사전에 정의된 범주 또는 클래스로 분류하는 작업을 의미합니다. 이를 통해 스팸 메일 필터링, 감성 분석, 주제 분류 등의 작업을 수행할 수 있습니다.
-
개체명 인식:
개체명 인식(Named Entity Recognition, NER)은 텍스트에서 명명된 개체(예: 사람 이름, 장소, 조직 등)를 식별하고 분류하는 작업입니다. 이를 통해 문서에서 중요한 정보를 추출할 수 있습니다.
-
기계 번역:
기계 번역은 한 언어로 작성된 문장을 다른 언어로 자동으로 번역하는 작업을 의미합니다. 이를 통해 다국어 커뮤니케이션을 원활하게 할 수 있습니다.
-
정보 검색:
정보 검색은 사용자의 검색 쿼리와 관련된 정보를 문서나 웹 페이지에서 검색하여 반환하는 작업을 의미합니다. 이를 통해 정보를 효율적으로 검색하고 접근할 수 있습니다.
-
문서 요약:
문서 요약은 긴 문서를 간결하고 요약된 형태로 변환하는 작업을 의미합니다. 이를 통해 대량의 텍스트 데이터를 빠르게 이해하고 파악할 수 있습니다.
-
감성 분석:
감성 분석은 텍스트의 감정이나 의견을 분석하는 작업을 의미합니다. 이를 통해 제품 리뷰, 소셜 미디어 데이터 등에서 감성을 파악할 수 있습니다.
이러한 자연어 처리 작업은 다양한 응용 분야에서 활용되며, 텍스트 데이터를 효율적으로 처리하고 분석하는 데에 중요한 역할을 합니다.
사전 학습된 모델 활용
ELMo는 미리 학습된 언어 모델을 활용하여 효과적인 전이학습을 수행할 수 있다. 새로운 작업에 적용하기 위해 추가 학습을 거침으로써 빠르고 효율적으로 모델을 개선할 수 있다.
결론
ELMo는 언어 모델의 다중 레이어 임베딩을 통해 자연어 처리 분야에서 혁신적인 발전을 이끌어내고 있다. 다층 임베딩을 활용한 이 알고리즘은 단어의 의미와 문맥을 더욱 정확하게 파악할 수 있으며, 이를 통해 다양한 자연어 처리 작업에서 뛰어난 성능을 보여준다. 더 나아가서, ELMo의 적극적인 활용은 자연어 처리 분야의 미래를 열어가는데 중요한 역할을 할 것으로 기대된다.



댓글
댓글 쓰기